// Part 0 — 成果展示
数据概览
3 人团队,6 个月,全程 Claude Code 开发。
我们造了什么
以下产品全部由 3 人团队 + Claude Code 完成。
系统架构
5 层分层架构,34 个仓库,从用户交互到基础设施全链路覆盖。
极限速度
Optima AI 做跨境电商 AI 平台,核心团队 3 个人,6 个月写了 126 万行代码,30 个仓库,8000 多次 commit。全程用 Claude Code 开发。
这个代码量和系统复杂度,按传统模式至少需要 20-30 人的团队。我们 3 个人做到了,靠的不是加班,而是从根本上改变了开发方式。
今天分享的不是理论,是我们踩了 6 个月坑之后总结出来的实战经验。分两部分:个人怎么用好 Claude Code,以及团队怎么围绕它协作。
AI Native 开发最大的变化,是工程师的角色从"写代码的人"变成了"做决策的人"。 学习、设计方案、审方案、理解原理、搭建工具链——这些才是人类该做的事。写代码交给 AI。
// Part 1 — 个人开发
01先学习、再做方案、再写代码
追问到能评判方案好坏
边界条件 · 验收标准
一次性通过率极高
为什么这是第一条
5000 行代码不过 30 分钟的事情。但写代码快,从来不是我们效率高的原因。真正的原因是:我们花了大量时间在写代码之前。
学习、做技术方案、审方案——这三步占了整个开发周期 70% 以上的时间。写代码反而是最短的环节。
第一阶段:学习
这是最容易被跳过的一步,也是最不应该跳过的一步。正确的做法是:先花 1-2 个小时,拿 Claude Code 当老师,上一课。
不是泛泛的问题,而是有深度的、追根究底的问题。每一个回答之后还要追问。结束的标志是:你觉得自己对这个领域的理解,已经足够去评判一份技术方案的好坏了。
极致案例:花 1 天学 AWS,产出了 41 篇文档、32,000 多行内容,覆盖 35 个 AWS 核心知识点。学习过程本身也产出了可复用的知识库。
第二阶段:做技术方案
Claude Code 缺少"边写边思考"的能力。你给它一个方案,它就照着方案写。方案里没提到的东西,它大概率不会主动考虑。必须把思考前置到方案阶段。
commerce-backend 在写任何一行代码之前,先有一份 1645 行的架构文档(ARCHITECTURE.md)。optima-business 先写了 1100 行的 TECH_SPEC.md。先有方案,再有代码。
第三阶段:写代码
方案做好了,写代码反而是最快的环节。5000 行代码 30 分钟,配合详尽的技术方案,一次性通过率非常高。
学习阶段实操建议
- 带着目标学——列出不确定的问题,一个一个问
- 追问到底——每一层回答都继续追问细节
- 要求对比——技术选型让它列对比表
- 问失败案例——"什么情况下会出问题?"
- 让它出题考你——答不上来的说明还没学透
- 沉淀成文档——让 Claude Code 整理讨论成文档
技术方案实操建议
- 不要一次让它写完整方案,先写大纲再展开
- 逐模块讨论,一个一个来
- 要求写清楚"为什么"
- 让它画图(Mermaid)
- 关注边界条件
- 给方案写验收标准
AI Native 开发中,写代码是最不重要的环节。学习和方案设计,才是你应该花最多时间的地方。
02选对工程基础设施
三个关键选择决定了效率天花板:TypeScript、Monorepo、CLAUDE.md。
TypeScript:让 AI 写的代码有静态检查
我们 30 个仓库,全部用 TypeScript。前端、后端、CLI、SDK、Lambda、基础设施脚本,无一例外。
- 训练数据量最大——Claude Code 对 TypeScript 的理解最深、一次性通过率最高
- 静态类型检查是刚需——能在编译阶段捕获大量错误,是 AI 代码质量的第一道防线
- 前后端同一种语言——类型定义共享,接口定义复用,前后端数据结构完全一致
- 生态丰富——NPM 是世界上最大的包管理器
Monorepo:让 Claude Code 看到完整上下文
Claude Code 只能看到当前仓库里的代码。Monorepo 让它自然而然就能看到所有相关代码——在写前端组件时直接去看后端的 API handler,确保请求格式完全一致。
案例:optima-ai-shell 一个仓库包含 5 个 TypeScript 包(ai-cli、session-gateway、web-ui、lambda-handler、agentcore-adapter),密切依赖,Claude Code 可以一次性改完所有相关代码。
CLAUDE.md:项目的知识库
CLAUDE.md 是你给 Claude Code 的项目说明书,决定了它对项目的理解深度。本质是把隐性知识显性化。
一份好的 CLAUDE.md 包含:项目概览、架构设计、开发约定、常见陷阱、开发部署流程、重要业务逻辑。
我们 30 个仓库几乎每个都有 CLAUDE.md。最短 148 行,最长 1062 行。commerce-cli 660 行,commerce-backend 521 行。
三个选择的效果是叠加的。TypeScript 给了类型安全,Monorepo 给了上下文共享,CLAUDE.md 给了项目知识。三者一起,质变。
03让 Claude Code 大量写自动化测试
你不知道 AI 写的代码对不对,但测试可以告诉你。在 AI Native 开发中,测试是"生存必需品"。没有测试的 AI 生成代码,就是一个黑箱。
两道防线:静态类型 + 自动化测试
| 防线 | 捕获问题 | 阶段 |
|---|---|---|
| 静态类型检查 | 参数类型不对、返回值不匹配、字段名拼错 | 编译时 |
| 自动化测试 | 业务逻辑错误、边界条件、异常处理 | 运行时 |
测试代码比例 1:1
功能代码行数和测试代码行数大致 1:1。传统团队做到 30% 覆盖率就不错了,但关键区别是:传统团队的测试是人写的,成本高;我们的测试是 Claude Code 写的,成本几乎为零。
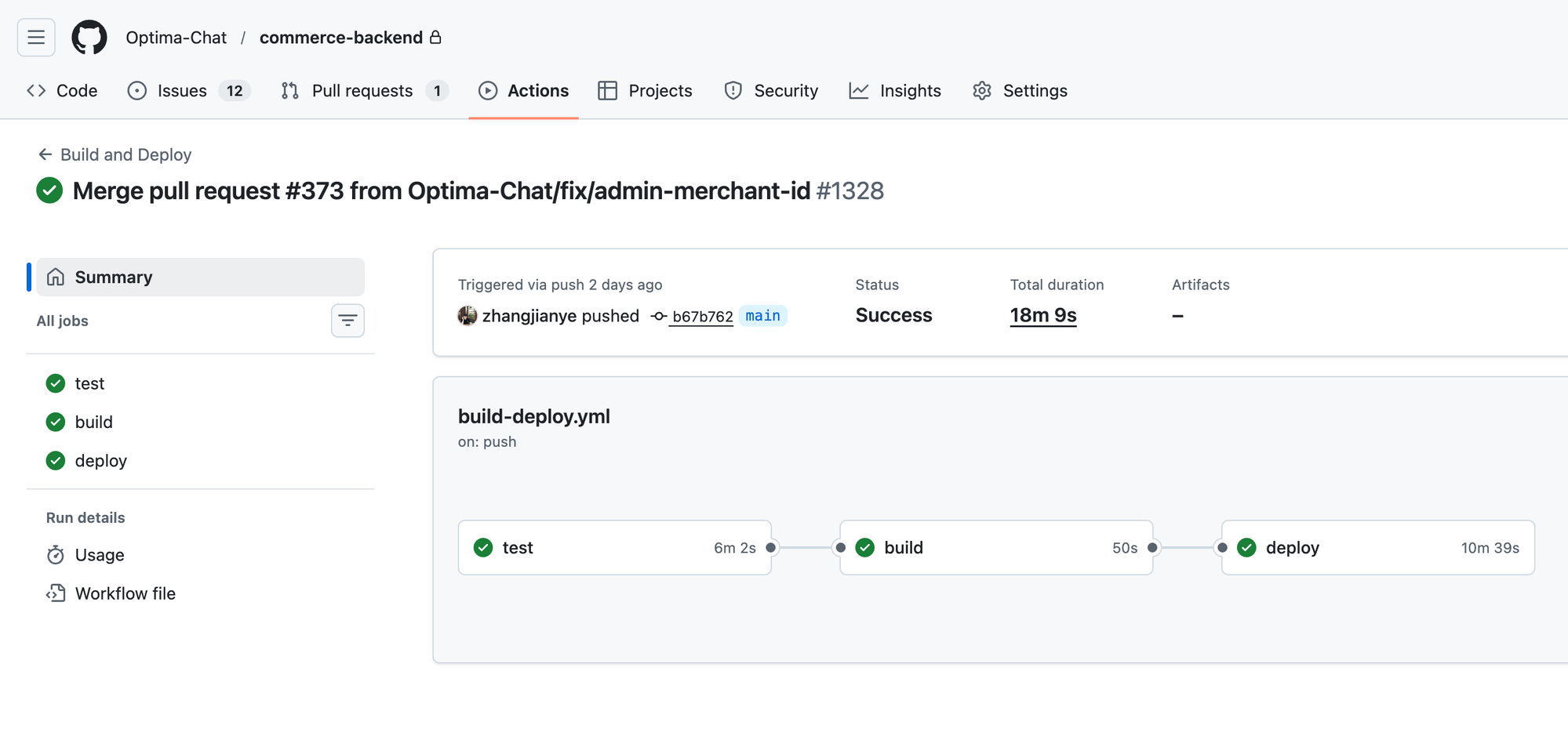
案例:commerce-backend 的 1555 个测试
1555 个测试用例,100% 通过率。覆盖 47 个数据模型的 CRUD 操作、45 个 Service 的业务逻辑、API 端点验证、权限控制、异常处理。
这 1555 个测试,都是 Claude Code 写的。你只需在让它写功能代码时附上一句"顺便把测试也写了"。
CI 集成:测试是合并的门禁
每次 PR 提交,CI 自动执行:TypeScript 编译检查 → ESLint 静态分析 → 全量测试。三步全过,PR 才允许合并。
让 Claude Code 大量写测试,是 AI Native 开发中成本最低、收益最高的实践。不要省这个"免费的保险"。
04多开是效率的来源
| 并行度 | 日产出 |
|---|---|
| 1 开 | ~5,000 行 |
| 4 开 | ~20,000 行 |
| 8 开 | ~30,000+ 行 |
日常 4 开,忙的时候 8 开。一个仓库一个 Claude Code 实例,同时推进多个仓库的任务。
多开的三个前提
- 技术方案必须足够细——多开本质上是对前置工作质量的兑现
- 每个仓库都有好的 CLAUDE.md——相当于给多个"新员工"发同一份入职手册
- 完善的测试——没有测试的多开,就像蒙着眼睛开多辆车
案例:optima-agent 三天 177 次 commit
2025 年 11 月 28 日到 30 日,三天时间产生了 177 次 commit,单日最高 70 次。三天完成一个完整的 AI Agent 框架。
多开与技术方案的关系
方案做到 60 分,只敢单开。方案做到 80 分,可以 2-3 开。方案做到 95 分,可以 6-8 开。你在技术方案上花的每一分钟,都在为多开创造空间。
3 个人写 126 万行代码,不是超人式的努力,是并行化带来的数学必然。
05要充分理解代码原理
定位可疑区域
原因和修复方案
判断假设是否合理
写代码修复
126 万行代码,我看过的不到 1%。但每个模块做什么、模块之间怎么交互、数据怎么流转、关键设计决策是什么,这些我都很清楚。这就够了。
"理解原理"意味着什么
- 知道架构和数据流——系统有哪些组件,它们之间怎么通信
- 知道设计决策背后的原因——为什么选 WebSocket 而不是 SSE?
- 知道每个组件的失败模式——WebSocket 断连、数据库超时、消息队列积压
- 不需要知道每一行代码——126 万行代码看不完,也不需要看完
核心 Debug 模式
案例:AI Shell 消息推送乱序
Claude Code 诊断为"网络延迟导致乱序"。但我了解架构——WebSocket 单连接、TCP 保序,网络延迟假设说不通。真正原因是异步数据库写入的顺序问题。给出正确方向后,十几分钟修复。
一个正确的方向性建议,抵得上十次错误的代码修改。人类的核心价值是方向判断。
// Part 2 — 团队协作
06给你的后端写个 CLI
- 1. 获取 auth token
- 2. 拼 Authorization header
- 3. 构造 JSON body
- 4. 拼完整 URL + query params
- 5. 发送 curl/fetch 请求
- 6. 解析返回的 JSON
- 7. 处理错误码和异常
- 1. optima product create --title "Test" --price 29.99
让 Claude Code 测一遍 API 端点,远比让它跑一条 CLI 命令慢得多,也更容易出错。
测 API 要处理什么?认证 token、请求头、请求体格式、URL 拼接、错误码解析——每一步都可能出问题。但 CLI 就是一行命令、一段输出,Claude Code 天然擅长。
CLI 让 Claude Code 能随意组合测试
有了 CLI,你可以直接在 Claude Code 里按任意需要组合功能来测试。不需要写测试脚本,不需要配 Postman,想测什么直接说。
# 创建商品 → 设置库存 → 创建订单 → 全流程验证
optima product create --title "Test" --price 29.99
optima inventory set --sku SKU-001 --quantity 100
optima order create --items '[{"sku":"SKU-001","qty":1}]'
optima order list --status pending --pretty同样的流程如果走 API,Claude Code 需要处理认证、拼 curl、解析返回值,每一步都可能卡住。CLI 把这些全部封装了。
案例:commerce-cli
我们给 commerce-backend 写了完整的 CLI 封装:19 个模块、280+ 条命令,覆盖商品、订单、库存、物流、退款、国际化等全部操作。
写 CLI 本身也是 Claude Code 最擅长的事——纯逻辑、纯文本、不涉及 UI,一次性通过率非常高。我们的 CLI 模块基本都是 Claude Code 一次写完的。
额外收益:CLI 可以直接给 AI Agent 用
我们最初写 CLI 是为了给 Claude Code 的 Skills 调用,替代 MCP 协议。但发现这套 CLI 同时解决了开发测试、人工运营、AI Agent 自动化三个场景。一套命令,三种用户。
写个 CLI 永远不亏。Claude Code 写得快、测得准、还能直接复用给 AI Agent。
07做团队自己的 Dev Skills
CLAUDE.md 是随身带的笔记本。Skills 是办公桌抽屉里的操作手册,需要的时候才拿出来翻。按需加载的知识文件。
7 个自定义 Skill
| Skill | 行数 | 功能 |
|---|---|---|
| logs | 205 | 通过 CloudWatch 查看服务日志(CI/Stage/Prod) |
| query-db | 211 | 查询数据库,自动管理 SSH 隧道 |
| generate-test-token | 331 | 自动注册测试账号、走 OAuth 流程、拿 Token |
| show-env | 185 | 通过 Infisical 查看环境变量 |
| use-commerce-cli | 64 | commerce-cli 使用说明 |
| read-code | 207 | 跨仓库读取代码(GitHub API) |
| restart-ecs | - | 重启 ECS 服务(Stage/Prod) |
实战案例:"Stage 的商品 API 返回 500"
开发者只说了这一句话。Claude Code 自动:查日志 → 发现 Database connection timeout → 查配置 → 发现 max_connections 过小 → 给出修复方案。全程全自动。
分发机制
npm install -g @optima-chat/dev-skills@latest一行命令搞定。NPM 包的 postinstall hook 自动复制 Skill 文件到 ~/.claude/。
Dev Skills 的本质:把"怎么操作"从人的记忆搬到 AI 的能力里。机构知识的编码化。
08充分利用 GitHub Issues 和 PR
团队成员之间的技术沟通,很大程度上是通过 Claude Code 写的 GitHub Issues 来完成的。Claude Code 永远不会偷懒。每个 issue 都像一份完整的技术报告。
跨仓库沟通
A 仓库的 Claude Code 发现了 B 仓库的问题,直接通过 gh 命令在 B 仓库创建 issue,把所有技术细节写进去。B 仓库的 Claude Code 打开 issue,直接开始修复。
真实案例
- Issue #33(23 个命令缺失)——Claude Code 自动对比 MCP 和 CLI 功能,发现 23 个缺失。同一天 PR #34 提交:17 个 commit、45 个文件、+4202 行代码。一天之内闭环。
- Issue #9(AI 输出格式优化)——Claude Code 发现表格格式浪费 50% 以上 token,推动了默认 JSON + --pretty 的设计决策
- Issue #94(跨仓库 JWT 错误)——在 hub 仓库发现问题,根因在 backend。Claude Code 自动创建跨仓库 issue 传递完整上下文
Issues + PR 变成了一个自动维护的知识库。不需要额外的文档写作工作,知识沉淀是开发流程的副产品。
09让 Claude Code 做 Code Review
两层审查
| 层级 | 审查者 | 审什么 |
|---|---|---|
| 第一层 | Claude Code | 测试覆盖、安全问题、性能问题、代码风格、错误处理 |
| 第二层 | 人类 | 架构决策、业务逻辑、系统设计的长期影响、方案合理性 |
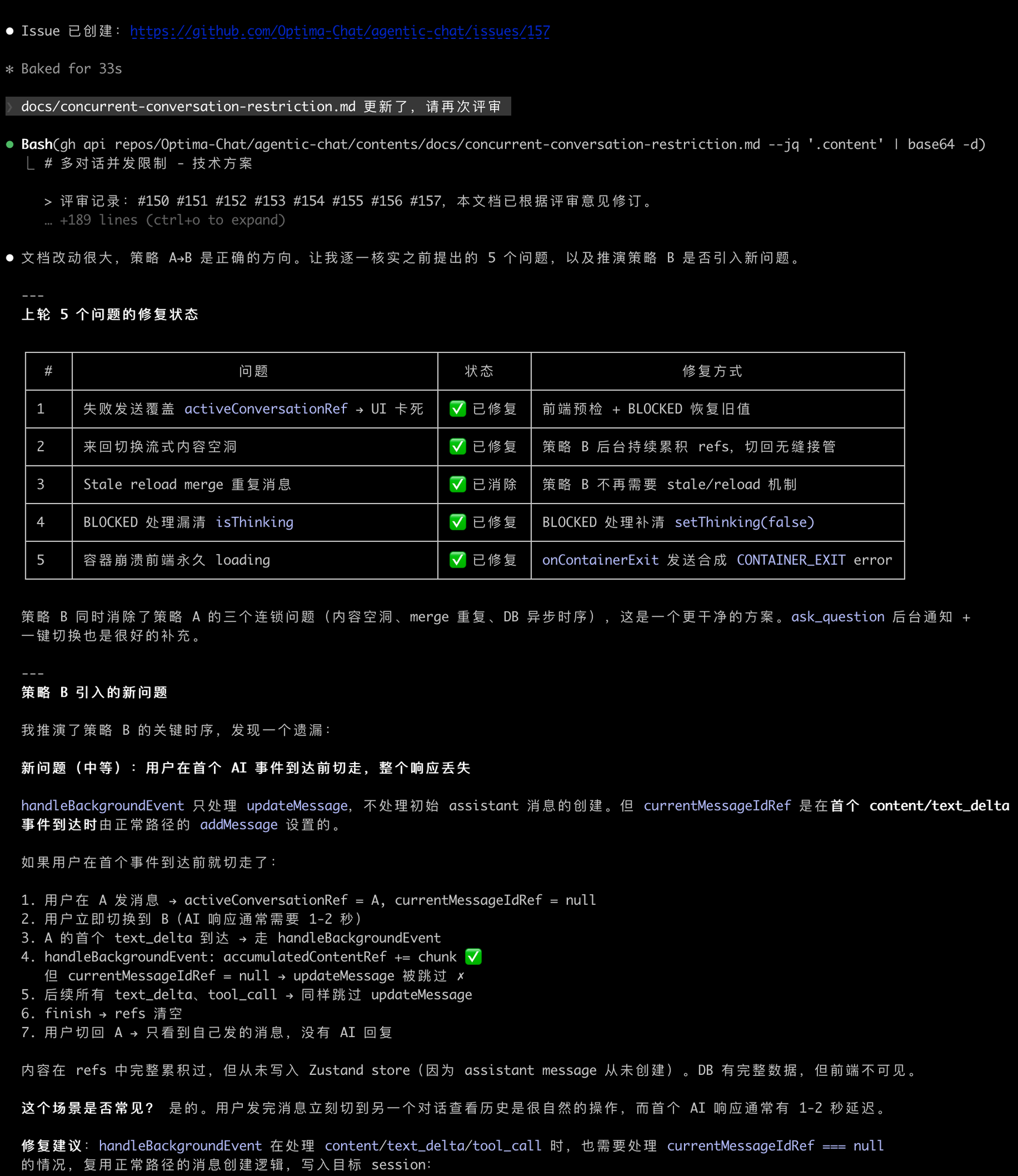
案例:commerce-backend 全面 Code Review
产出了一份 291 行的评审报告,从 8 个维度评分:
| 维度 | 评分 |
|---|---|
| API 设计 | 9/10 |
| 数据库设计 | 9/10 |
| 测试覆盖 | 9/10 |
| 国际化 | 8.5/10 |
| 服务架构 | 8/10 |
| 安全性 | 7.5/10 |
| 错误处理 | 7.5/10 |
| 性能 | 6.5/10 |
还给出了三阶段修复计划:立即修复(安全)→ 1-2 周(性能)→ 3-8 周(架构优化)。
让贵的人做贵的事,让 AI 做重复的事。 Code Review 不再是做不做的选择题,它应该是每个团队的标配。
10充分利用 Claude Code 的文档能力

当一个东西的成本从"一周"降到"几小时",你对待它的态度就应该变。
Claude Code 擅长写的文档
- 架构文档——60KB 覆盖 30 个仓库的完整架构(OPTIMA_COMMERCE_ARCHITECTURE.md),含 Mermaid 图
- 月报——自动分析 325 次 commit、14 个活跃仓库,产出结构清晰的技术月报
- 技术 RFC——753 行的并发对话串台问题 RFC,经 5 轮评审通过
- API 文档和新人引导——从零到卖货的完整 Getting Started Guide
- 学习文档——41 篇 AWS 学习文档,学习过程自动产出知识资产
不止文档:你现在看的这个网页
每个都是 Claude Code 从零生成,从需求到上线不超过一天。不用再做 PPT 了——直接让 Claude Code 生成网页,又快又好,还能随时更新。
PPT 做完就死了。网页是活的——可以加链接、嵌截图、点击放大、响应式适配手机、一键部署到公网。信息密度和表现力都远超 PPT。
文档和 AI 的正循环
好的文档 → 更好的 AI 理解 → 更好的代码和文档产出 → 更好的文档。你选择进入哪个循环,直接决定了团队使用 AI 的效率上限。
把文档当作基础设施来投资,而不是当作成本来控制。在 AI Native 开发的世界里,文档不是负担,是杠杆。
11用 Claude Code 做 BI 分析

传统 BI vs Claude Code BI
| 传统 BI | Claude Code BI | |
|---|---|---|
| 定量分析 | DAU、转化率、Token 消耗 | 同上 |
| 定性分析 | 做不了 | 从对话记录提炼系统问题、用户画像 |
| 回答的问题 | "发生了什么" | "为什么发生" |
系统问题分析
分析 9 个对话、10 位用户,发现 7 个系统问题。每个问题都有具体错误信息、涉及用户、根因分析和改进建议。
用户画像
Claude Code 读完每个用户几百条对话后理解出用户画像——重度运营用户、单品类深度研究型、新卖家冷启动型。这些不是从数据库字段拼的,是理解出来的。
传统 BI 告诉你"DAU 下降了 23%",Claude Code 告诉你为什么。相当于每周做一次全面的用户调研,成本几乎为零。
// 如何开始
三个场景,三种路径
听完方法论,下一步是什么?取决于你的场景。
场景一:已有的内部项目
存量项目有三个零风险的切入点,今天就能开始。
1. 补自动化测试——存量项目最大的障碍是"没有测试、不敢动"。让 Claude Code 先给核心模块补上测试,零风险、立刻见效。有了测试,后续改 bug、加功能都可以放心交给 AI。
2. 写文档——让 Claude Code 读完整个仓库,产出架构文档、API 文档、部署手册。以前写文档要一周,现在几小时。文档本身就有价值,同时 CLAUDE.md 让 AI 理解项目上下文,为后续协作打基础。
3. 做 BI 分析——让 Claude Code 直接读数据库、读日志,生成分析报告。不需要改任何代码,纯只读操作,零侵入。管理层立刻看到 AI 产出价值。
三件事都是零风险、不碰生产代码,但能让团队立刻看到 AI 的产出能力。信心建立起来了,后续推进就顺了。
场景二:新项目,用 3 人交付 20 人的活
AI Native 开发让小团队具备大团队的交付能力。这会重塑 IT 服务的经济模型。
挑一个真实的客户项目——行业 SaaS、数据中台、API 中台都行——组一个 3 人小队:
- 1 人架构师——写 CLAUDE.md、定技术方案、做 Code Review。不写代码,只把控方向和质量。
- 2 人 AI 操作员——每人同时开 2-4 个 Claude Code 实例。日常工作是:拆任务、给 AI 下指令、审结果、合代码。
节奏:第 1 周只搭基础设施(TypeScript + Monorepo + CI + CLAUDE.md),不写业务代码。第 2 周开始业务开发,每天 50-70 commit 是正常速度。2-3 个月交付,传统方式要半年 20 人。
算一笔账:成本降 70%,交付速度快一倍,利润率从 10-15% 拉到 50%+。一个项目跑通,数据本身就是最好的汇报材料。
场景三:做 Coding Agent 产品给客户用
Coding Agent 会成为写代码的水和电。中国企业市场目前没有领导者。
中美之间的技术壁垒意味着 Claude Code 这样的产品进不了国内。但需求是真实的——每一个写代码的团队都会需要 Coding Agent,就像每个团队都需要 Git 和 CI 一样。这是一个确定性极高的巨大市场,而且目前没有人占住企业这个位置。
为什么是现在:国内大模型的编码能力正在快速追赶(DeepSeek、Qwen),底层能力的差距在缩小。但光有模型不够——企业客户需要的是:私有化部署、数据合规、行业定制、与内部工具链集成。这些恰恰是模型厂商不擅长、而 IT 服务商擅长的。
怎么做:基于 OpenCode 等开源 Coding Agent 框架构建,接入多种国产模型,不绑定单一供应商。先在自己的项目里跑通全流程(场景一和场景二),积累实战经验,然后把这套能力产品化,卖给客户。
先做起来,比等模型成熟更重要。今天先把 Agent 产品的架构和场景跑通,等模型能力再上一个台阶,就是直接起飞。
不管哪个场景,最重要的是现在就开始。AI Native 开发不是未来的事——它已经在发生。先跑起来的团队,积累的经验本身就是壁垒。
// 附录
12常见问题与局限
踩过的坑
- 不做方案直接让 AI 写——改了五六轮推倒重来,技术方案做好后 30 分钟一次通过
- 多开合并冲突——两个实例改了同一个公共模块,花了大半天理清。教训:每个 Claude Code 实例使用单独的 Git Worktree,物理隔离工作目录,合并时才处理冲突
- 用 Python 写后端——大量时间花在检查和修正 lint 错误上。动态类型语言的 lint 规则多且碎,AI 经常顾此失彼。换 TypeScript 后这类问题几乎消失——这也是我们强烈推荐 TypeScript 的原因之一
UI 开发:精确复现设计稿仍是难点
后端逻辑、CLI、测试这些 AI 写得很好,但前端要精确还原设计稿(像素级对齐、交互细节、响应式适配)目前仍有明显差距。
这不只是我们的问题——国内外大厂都在投入多模态 Coding Agent 研究。我们自己的 iSING Lab 研究课题显示:
| 模式 | 准确率 |
|---|---|
| 文本 Coding Agent | ~80% |
| 视觉输入(截图→代码) | ~36% |
| 差距 | 43 个百分点 |
这是当前整个行业的研究热点。实际操作中,后端逻辑基本一次通过,前端还原设计稿需要 AI 反复调整多轮才能到位——接受这个节奏,不要期待一步到位。
关于代码质量
单论代码质量——命名规范、错误处理、风格一致性——Claude Code 写的代码在任何情况下都比人写的好。真正依赖技术方案质量的,是业务逻辑的正确性。方案粗糙,AI 会写出漂亮但逻辑错误的代码;方案清晰,AI 一次通过的概率极高。
Claude Code vs Codex vs Gemini CLI
| Claude Code | OpenAI Codex | Gemini CLI | |
|---|---|---|---|
| 模式 | 终端 Agent | 云端沙箱 | 终端 Agent |
| 模型 | Claude Sonnet/Opus | codex-mini (o4-mini) | Gemini 2.5 Pro |
| 本地文件访问 | 直接读写 | 需上传到沙箱 | 直接读写 |
| 多开并行 | 4-8 个实例 | 支持多任务 | 支持 |
| 工具生态 | MCP + Skills + Hooks | 有限 | MCP + Extensions |
| 工程能力体感 | 断层领先 | 轻量任务可用 | 快速追赶中 |
实际体感:Claude Code 在大型项目中理解上下文、做架构决策、一次性写对复杂逻辑的能力明显领先。Codex 能力不差,但云端沙箱模式导致每个任务都要等,节奏明显慢,不适合需要快速迭代的场景。Gemini CLI 响应快,但在复杂工程任务上的理解力和 Claude 有明显差距,经常需要多轮纠正。
以上为个人主观使用体感,未做系统化定量评测。所有工具都在快速演进,仅供参考。
数据安全
企业最关心的问题:代码会不会被模型厂商拿去训练?
- Claude Code——Anthropic 明确承诺:API 调用的数据不用于模型训练。代码在传输和处理过程中加密,不会被存储或学习。对于大部分企业项目,这个保障已经足够。
- AWS Bedrock——如果需要更强的隔离,可以通过 AWS Bedrock 调用 Claude,数据不出你的 AWS 账户。适合对数据驻留有合规要求的企业。
- 完全本地部署——对于政府、金融等涉密场景,可以用 OpenCode + 国产模型(DeepSeek、Kimi K2),代码完全不离开内网。能力有差距,但数据安全零风险。
知识产权
中国法院认定:AI 生成内容如果体现了使用者的独创性贡献,使用者享有完整著作权。"先学习、做方案、审方案、再让 AI 写代码"的流程,天然就是大量人类智力投入的证据。
供应商依赖
11 条实践中大部分不依赖特定工具。核心资产沉淀在 CLAUDE.md、测试、文档、Issues/PR 里——这些都是标准格式的文件,不绑定任何工具。OpenCode 是成熟的开源替代。
